안녕하세요!
오늘은 영상 편집에서 주로 사용하는 자동 자막 관련한 정보를 가져왔습니다.
제가 영상 편집을 하다 보니 자막을 달 일이 있었는데
찾아보니 주로 아래 것들이 유명하더라구요.
* 프리미어 프로
* Vrew (Whisper AI)
저는 파이널컷을 사용하고 있어서 프리미어 프로는 사용할 수 없고
vrew를 사용해봤는데, 10분이 무료 사용시간이라
제대로 사용할 수 없었습니다...
그래서 무료로 자막을 만들어낼 수 있는 방법이 없을까 했는데
있었습니다!!
설치하는 방법부터 사용하는 방법까지
전부 간단하게 알려드리겠습니다 ㅎㅎ (코딩 전혀 모르셔도 됩니다)
Whisper AI란?
그래도 뭔지는 간단히 알고 가면 좋겠죠?
한번 슥 읽어보세요 중요하진 않습니다.
(시간 없으면 패스!)
Whisper AI는 OpenAI에서 개발한 오픈소스 범용 음성 인식 모델입니다. 방대한 양의 음성 데이터셋으로 훈련되어 다양한 언어와 음성 스타일을 높은 정확도로 인식하고 텍스트로 변환하는 능력을 가지고 있습니다. 다국어 음성 인식, 음성 번역 등의 기능을 수행할 수 있어 회의록 작성, 강의 내용 요약, 영상 자막 생성 등 활용 범위가 매우 넓습니다.
준비물 (몰라도 아무상관없어요 대충 읽으세요)
- 인터넷에 연결된 맥북: 설치 및 모델 다운로드를 위해 필요합니다.
- Xcode Command Line Tools: Python 환경 구성에 필요합니다.
- Python 3.8 이상: Whisper AI는 Python 기반으로 작동합니다.
- git: GitHub 저장소를 복제하는 데 사용됩니다.
- FFmpeg: 오디오 파일을 처리하는 데 필요합니다
설치 방법
Whisper AI를 맥북에 설치하는 가장 쉬운 방법은 Homebrew와 whisper-cpp를 이용하는 것입니다. whisper-cpp는 Whisper 모델을 C++로 구현하여 더 빠르게 실행할 수 있도록 해주는 프로젝트입니다.
1. Homebrew 설치
Homebrew는 맥북에서 소프트웨어를 쉽게 설치하고 관리할 수 있도록 돕는 패키지 관리자입니다. 이미 설치되어 있다면 이 단계를 건너뛰셔도 됩니다.
터미널 앱을 실행합니다 (Command + Spacebar를 누른 후 "터미널" 검색). 그리고 다음 명령어를 입력하고 엔터를 누릅니다.
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
설치 과정 중에 비밀번호를 입력하라는 메시지가 나타날 수 있습니다. 화면에 뜨는 안내에 따라 진행하시면 됩니다.

이런식으로 뜨면, 비밀번호를 입력해주면 됩니다!
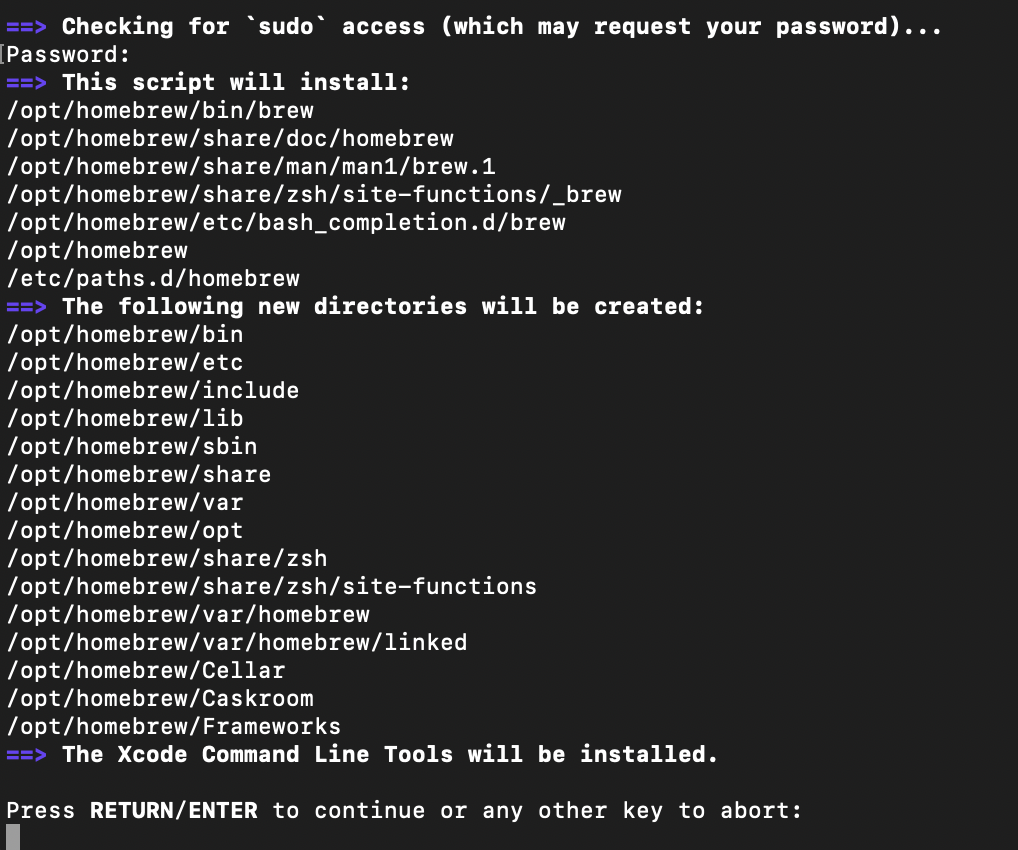
요렇게 뜨는건, 이런것들을 설치할거다 하고 list up만 해주는 거라
'엔터' 한번 더 눌러주세요
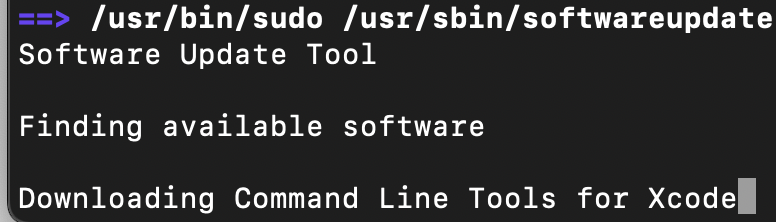
저는 요게 뜨고 10분 넘게 걸리고 있는데, 멈춘게 아니니까 그냥 기다려주시면 됩니다.
(인터넷에서 다운로드 받고 있는 중이라 오래걸릴 수 있으니 기다려주세요)
모든게 완료되면 아래처럼 뜰거에요!
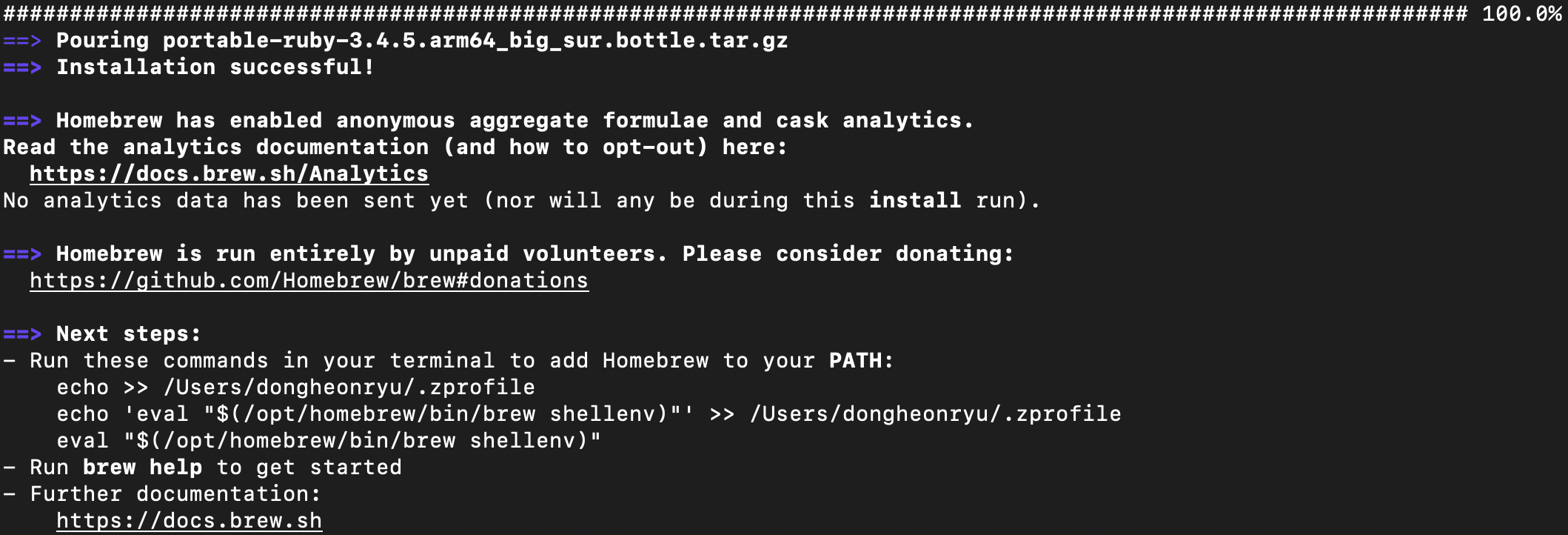
여기 보면 중간에 next step에 적혀있는 3줄 있죠?
그 부분은 terminal 에 그냥 복사해서 입력해주세요
(brew 라고 치면 이게 뭔 프로그램인지 멍청해서 몰라서, 알려주는 과정이라고 생각하시면 됩니다)

이렇게 해보고
terminal에서
brew --version이렇게 입력하면 설치가 잘 되었다면 버전이 뜰거에요

homebrew
3. FFmpeg 설치
Whisper는 다양한 오디오 형식을 처리하기 위해 FFmpeg이 필요합니다. Homebrew를 통해 쉽게 설치할 수 있습니다.
brew install ffmpeg
위랑 동일해서 추가 설명은 하지 않겠습니다
그냥 엔터 치면 알아서 설치 다 끝나요!
4. Python 환경 설정 및 Whisper 설치
Whisper는 Python으로 개발되었으므로, 적절한 Python 환경을 설정하는 것이 중요합니다. 가상 환경을 사용하는 것을 권장합니다.
4.1. 가상 환경 생성 및 활성화
프로젝트를 저장할 적절한 디렉토리로 이동한 후 가상 환경을 생성하고 활성화합니다. 예를 들어, whisper_project라는 디렉토리를 생성하고 그 안에서 작업한다고 가정합니다.
mkdir whisper_project
cd whisper_project
python3 -m venv venv_whisper # 'venv_whisper'라는 이름으로 가상 환경 생성
source venv_whisper/bin/activate # 가상 환경 활성화
가상 환경이 활성화되면 터미널 프롬프트 앞에 (venv_whisper)와 같은 표시가 나타납니다.

이렇게 아래쪽에 떴죠?
이거 가상환경 설정인데, 몰라도 되는건데
하는 이유는, 그냥 지금 설치하는 것들이 다른 프로그램에 영향을 주지 않기 위해서
그냥 방 하나 만들어놓고 거기다가 때려박고 있다고 생각하시면 편해요.
그럼 방만 폐쇄하면 아무 일 없던것처럼 보일테니까요!
(이해 안되면 그냥 따라만 하셔도 무방합니다)
4.2. Whisper 설치
이제 가상 환경이 활성화된 상태에서 Whisper를 설치합니다.
pip install -U openai-whisper
이 명령어는 Whisper 패키지와 모든 필요한 Python 의존성을 설치합니다.
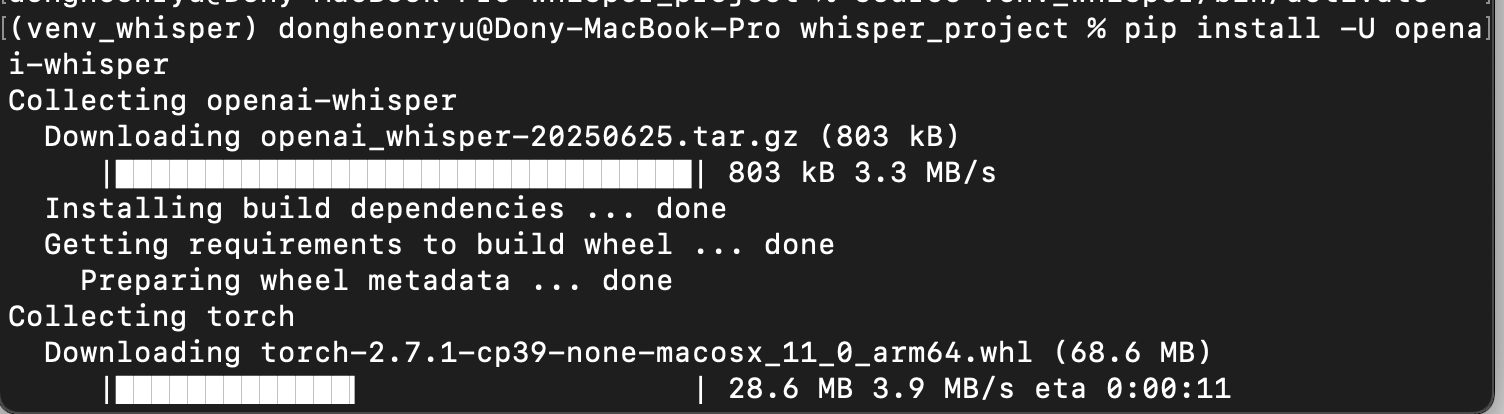
이런식으로 쭉 설치 될거에요!
이것도 그냥 가만히 두면 됩니다.
여기까지 하면 설치가 완료 되었습니다!
5. 모델 다운로드 (첫 실행 시 자동)
Whisper는 음성-텍스트 변환을 위해 사전 훈련된 모델을 사용합니다. 모델은 tiny, base, small, medium, large 등 다양한 크기로 제공됩니다. 모델 크기가 클수록 정확도가 높지만, 다운로드 시간이 길고 더 많은 메모리와 처리 능력을 요구합니다.
별도로 모델을 다운로드할 필요는 없으며, Whisper를 처음 실행할 때 지정된 모델이 자동으로 다운로드됩니다.
Whisper AI 사용하기
설치가 완료되었다면 이제 Whisper AI를 사용하여 오디오 파일을 텍스트로 변환할 수 있습니다.
1. whisper CLI (명령줄 인터페이스) 사용
가장 간단한 방법은 설치된 whisper CLI 도구를 사용하는 것입니다. 가상 환경이 활성화된 상태에서 다음 명령어를 실행합니다.
whisper "음성 파일 경로" --model base
- "음성 파일 경로": 변환할 오디오 파일의 경로를 입력합니다. 예를 들어, /Users/사용자이름/Desktop/my_audio.mp3와 같이 입력할 수 있습니다. 터미널에 파일을 드래그 앤 드롭하면 경로가 자동으로 입력됩니다.
- --model base: 사용할 모델의 크기를 지정합니다. tiny, base, small, medium, large 중 하나를 선택할 수 있습니다. 처음 사용하는 모델은 자동으로 다운로드됩니다.
예시:
바탕화면에 있는 my_meeting.mp3 파일을 base 모델로 변환하는 경우:
whisper "/Users/사용자이름/Desktop/my_meeting.mp3" --model base
명령어 실행 후, 오디오 파일과 동일한 디렉토리에 .txt, .vtt, .srt, .tsv, .json 등 다양한 형식의 텍스트 파일이 생성됩니다.
2. Python 스크립트에서 사용
Python 코드를 통해 Whisper를 직접 호출하여 사용할 수도 있습니다.
import whisper
# 모델 로드 (처음 로드 시 자동으로 다운로드)
model = whisper.load_model("base")
# 오디오 파일 변환
result = model.transcribe("음성 파일 경로")
# 결과 출력
print(result["text"])
이 코드를 transcribe_audio.py 파일로 저장한 후, 터미널에서 python transcribe_audio.py로 실행할 수 있습니다.
추가 옵션 및 활용 팁
- 언어 지정: 특정 언어의 음성인 경우 --language 옵션을 사용하여 정확도를 높일 수 있습니다. 예를 들어, 한국어의 경우 --language Korean 또는 --language ko를 사용합니다.
-
Bash
whisper "음성 파일 경로" --model base --language Korean - 장치 지정: GPU(MPS)가 있는 맥북 Pro/Max 사용자라면 --device mps 옵션을 사용하여 GPU 가속을 활용할 수 있습니다.
-
Bash
whisper "음성 파일 경로" --model medium --device mps - 출력 형식: --output_format 옵션을 사용하여 원하는 출력 파일 형식을 지정할 수 있습니다. (기본값은 모든 형식)
-
Bash
whisper "음성 파일 경로" --output_format txt - 번역 기능: --task translate 옵션을 사용하여 음성을 영어로 번역할 수 있습니다.
-
Bash
whisper "음성 파일 경로" --model base --task translate실제로 제가 사용한 터미널 명령어는 아래와 같습니다.
whisper "/Users/username/Documents/my_lectures/lecture_20250727.m4a" \ # 변환하고 싶은 음성 경로
--model medium \ # 변환 원하는 모델 선택. 성능마다 다른데, 일단 medium으로 해보고 퀄리티가 낮은 경우 올리세요
--language ko \ # 한국어 기반이라는 뜻
--device mps \ # mac silicon 유저(m1, m2 등) 는 요 옵션 쓰세요!
--output_dir "./lectures" \ # 어디에 파일이 생성될지 정하기
--output_format txt,srt \ # txt와 srt 파일로 출력
--word_timestamps True # 단어 별 timestamp를 지정해서 시작 종료 지점 선택, srt의 경우는 필요함.
요렇게 수행하니까

요렇게 뭔가 만들어지고 있습니다.
근데 용량이 이렇게 크지 않은데... 혹시 뭔가 잘못올린건 아닌지 두렵긴하네요 ㅋㅋㅋ
하지만 결과적으로 잘 나왔습니다!
솔직히 한번 설치는 귀찮지만
이거 자막 뽑겠다고 vrew같은거 결제하기 싫으신 분들은
한번 설치해서 사용하는 것 추천드립니다!
(귀찮으신 분들은 vrew같은거 쓰시면 편할거에요
3줄 요약
- Xcode Command Line Tools, Homebrew, FFmpeg을 설치하여 환경을 준비합니다.
- Python 가상 환경을 생성하고 pip install -U openai-whisper로 Whisper를 설치합니다.
- whisper "음성 파일 경로" --model [모델명] 명령어로 오디오를 텍스트로 변환합니다.
- OpenAI Whisper GitHub 저장소: https://github.com/openai/whisper
댓글